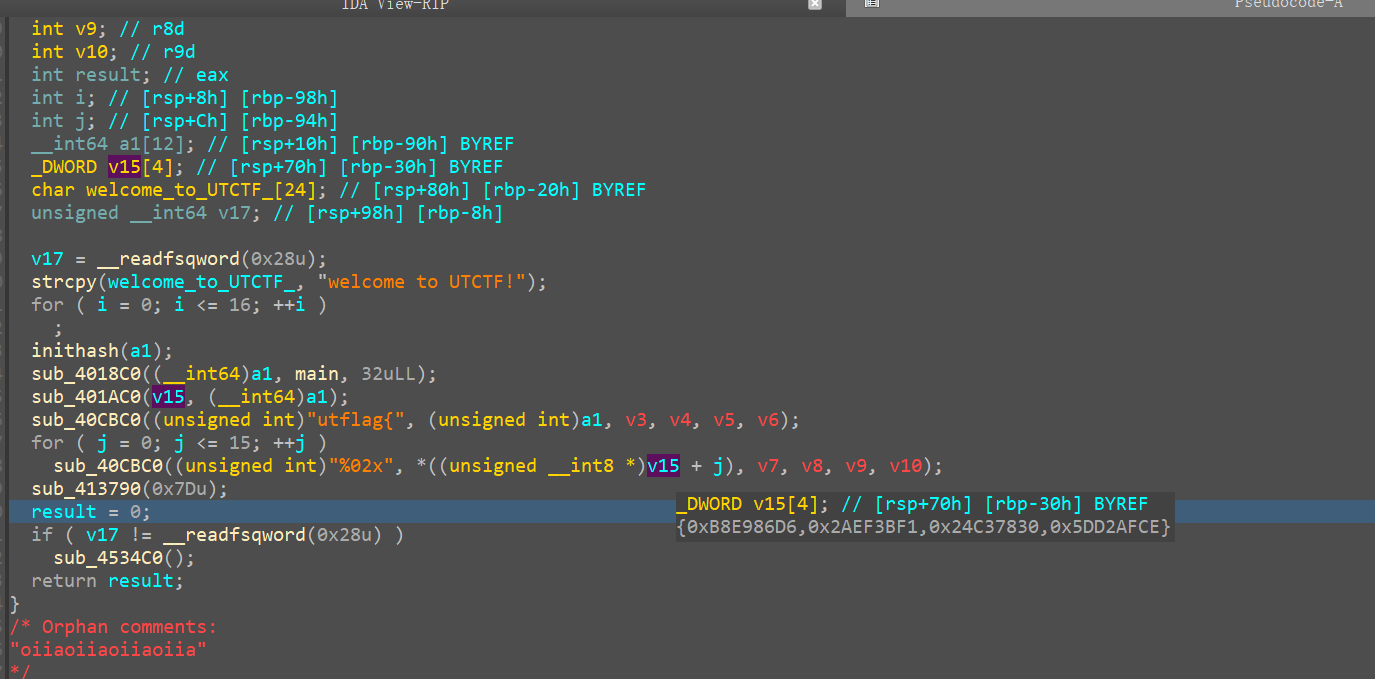
Ostrich Algorithm 还可以在汇编里面把call exit nop掉,直接动调到最后可以拿到md5值
Safe Word 逻辑上可能有点不好理解,我们先理一下逻辑。
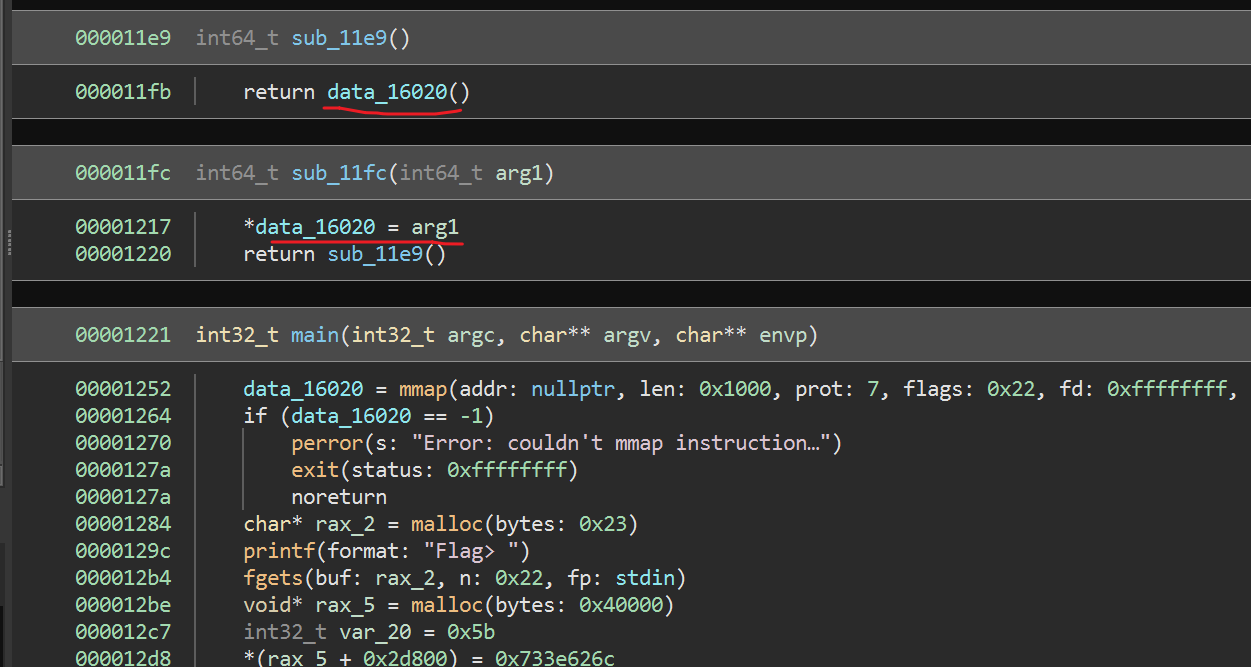
下面是main函数和一个sub_11e9()和sub_11fc(arg1),使用了BN反编译。
main函数开头使用了一个mmap函数分配了一块可以用于执行的内存,也就是说data_16020中的内容可以被作为代码执行。我们的输入被放入了rax_2中。并且还初始化了一个值var_20=0x5b。然后以我们的输入和var_30计算出索引获取rax_5中的值,作为参数传入sub_11fc()中,在上面分析sub_11fc()函数其实就是把rax_5的值作为了函数(代码)执行。既然是作为指令执行。那么这肯定就是是汇编的字节码,这四字节数据是一段汇编代码,被sub_11fc()执行,并把返回值赋给var_20用作下一次索引的计算。依次遍历完我们的输入。
1 2 for i in range (32 ): var_20 = f( rax5[ (input [i] + var_20 << 8 ) << 3 ] )
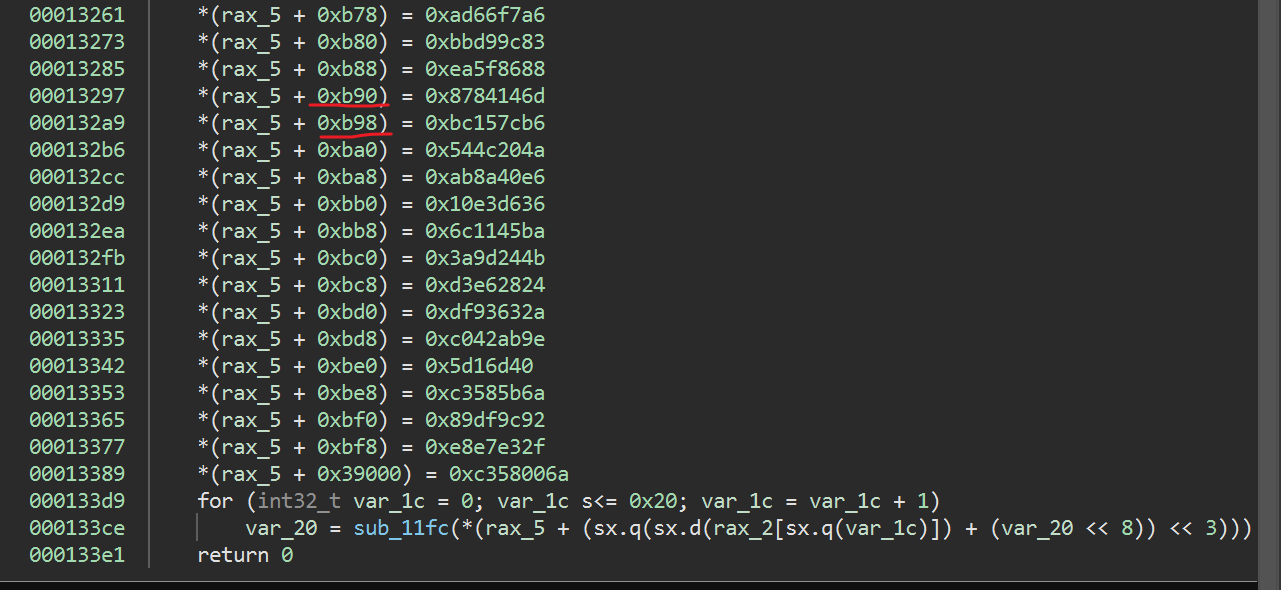
我们的输入在一次的循环中是可以不同的,范围是(32–>127),而var_20在一次循环中是不变的,有没有想过var_20的本质是什么?var_20在每次计算时都被左移了8位,假设var_20是0xff那么 0xff<<8 == 0xff00;此时与input[i]相加刚好构成了一个范围(0xff20–>0xff7f)。那么外面的”<< 3”是干嘛的?观察一下rax_5的索引间隔是8,”<<3”其实就是乘8,所以我们计算出的值要*8才是rax_5的索引。每次执行完代码后都会更新var_20的值,于是范围发生了改变,假设改变后的var_20 = 0x11于是范围改变,(0xff20–>0xff7f) –> (0x1120–>0x117f)。有没有一种感觉,rax_5被分成了许多的块,而var_20其实就是某一个块的索引,每一个块中又会指定下一个块的索引?再想一下,这和函数的跳转是不是有异曲同工之处?看一下rax_5的值发现确实是分块的。我们知道flag的开头是”utflag{“不妨动调看看执行的指令到底是什么。在call处下断点进去查看。再继续运行几次看看,发现指令形式也是一样的。
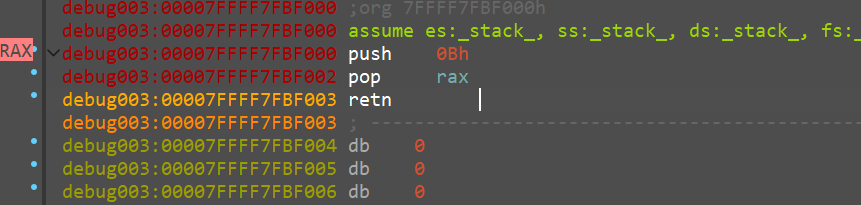
函数直接返回了0x0B,也就是下一个块的索引,这下就真相大白了。
其实主要的逻辑就是函数跳转,var_20是函数的基地址,我们要用输入的字符控制函数执行指令的地址(基地址+字符),使函数直接跳转到下一个函数,只要遍历完所有的函数,我们的输入就是flag。
我们可以计算出每一段函数的基地址,然后遍历所有可见字符,如果匹配到”0x6a, l[i + 1], 0x58, 0xc3(push xx pop rax retn)”这条指令,说明这个字符就是正确的(这里的执行顺序就是函数的排布顺序)。
那么这题目的意义是什么呢?我们的输入可以看作是一个漏洞,我们可以通过构造一个输入来控制函数的执行流程(控制流入侵),达到自己想要的目的,那么这就完成了一次入侵。我们逆向自己的pwn题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 def parse_data (data ): entries = data.strip().split(";" ) values = dict () for entry in entries: if "=" in entry: str = entry.split("=" ) index = str [0 ].strip()[3 ::].replace(']' ,'' ) value = str [1 ].strip() values[int (index)]=list (int (value.replace("LL" ,'' )).to_bytes(4 ,"little" )) return values data = """ v7[23296] = 1933468268LL; v7[23297] = 729031286LL; v7[23298] = 2575079303LL; v7[23299] = 1475628389LL; v7[23300] = 243385641LL; v7[23301] = 1799261851LL; ...... """ code = parse_data(data) l = [] op = 91 path = [] path.append(91 ) i =1 for j in code: dex = j // 256 if dex == path[i-1 ] : continue path.append(dex) i+=1 print (path)flag ='' for l in range (len (path)): for char in range (32 ,128 ): try : if code[(char + op * 256 )]==[0x6a ,path[l+1 ],0x58 ,0xc3 ]: flag += chr (char) op = path[l+1 ] break except : continue print (flag,len (flag),len (path))
map 就是把字符用五个数字表示,输入所有可见字符然后导出表就行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 text ="" for i in range (32 ,127 ): text += chr (i) print (text)str1 = text[:35 :] str2 = text[35 :35 +35 :] str3 = text[35 +35 ::] print (str1,str2,str3)table = dict () output1 ="4916849171491704917349172491754917449161491604916349162491654916449167491664915349152491554915449157491564915949158492094920849211492104921349212492154921449201492004920349265" output2 = "4920249205492044920749206491934919249195491944919749196491994919849185491844918749186491894918849191491904936949368493714937049373493724937549374493614936049363493624936549364" output3 ="4936749366493534935249355493544935749356493594935849345493444934749346493494934849351493504940149400494034940249405494044940749265492654926549265492654926549265492654926549265" a = output1 + output2 + output3 value1 = [a[i:i+5 ] for i in range (0 ,len (a),5 )] for i,j in zip (text,value1): table[j] =i print (table)m = "4934849349493674935749360493664940249346493534935849348493574936549351493644937449348493464936449365493744935349360493464935449364493574935749374493494935349358493594935449404" mm =[m[i:i+5 ] for i in range (0 ,len (m),5 )] for i in mm: print (table[i],end='' )
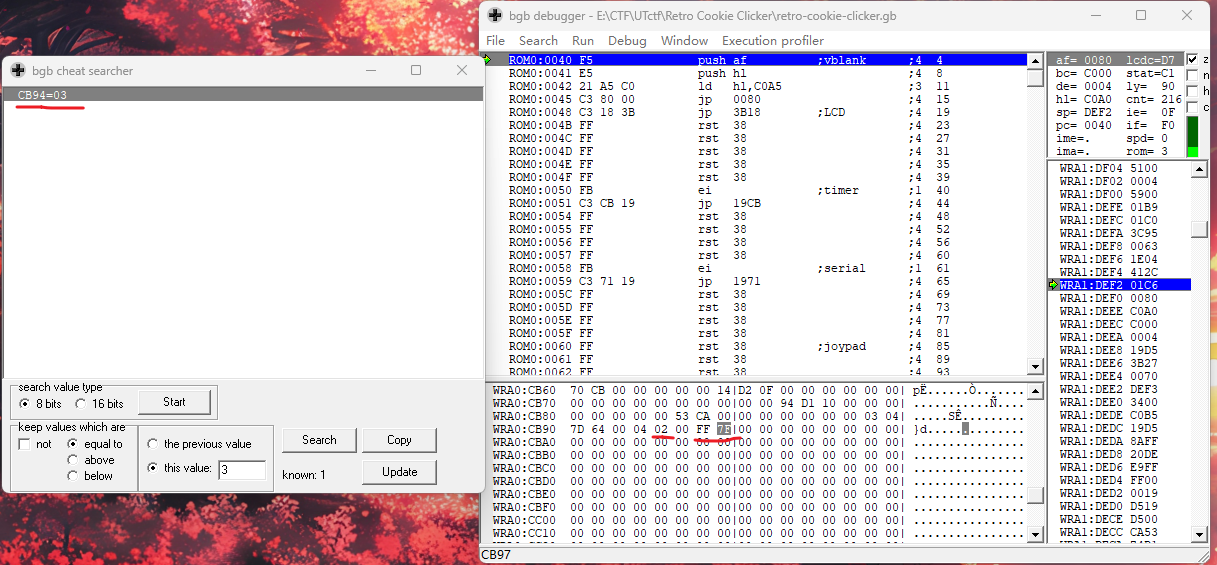
Retro Cookie Clicker gameboy游戏用gbg模拟器运行。通过不断的改变值搜索内存中的值来找到关键内存位置。
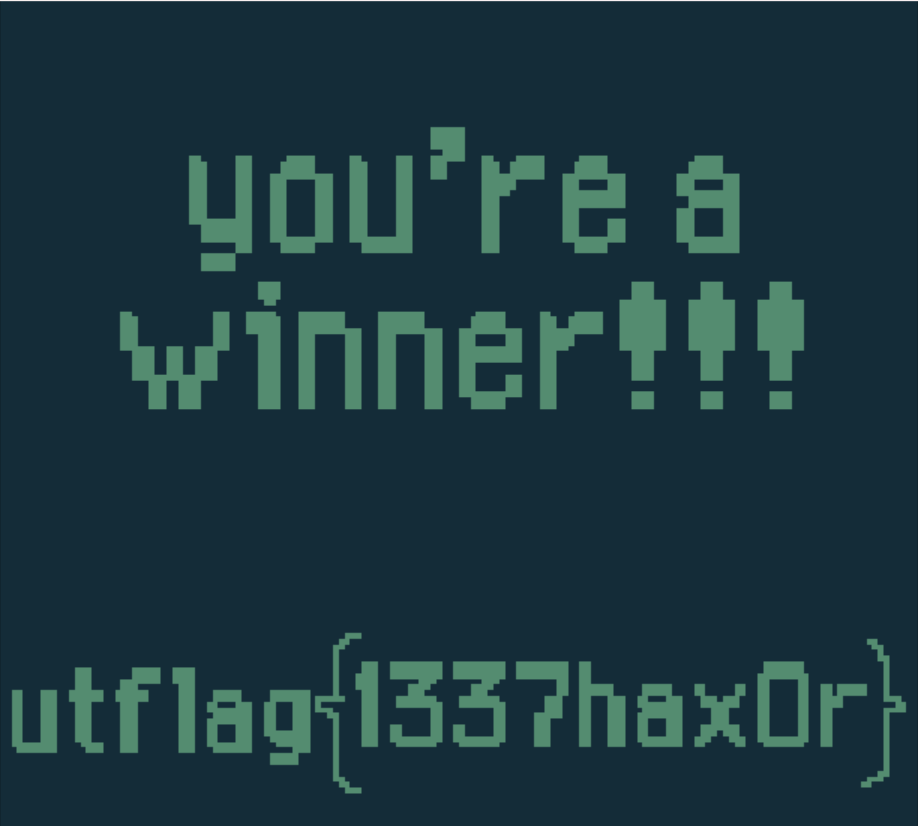
这里我们搜索豆子的值,当豆子为3时发现只有CB94处的值为3。这类游戏的变量存储一般就在一块内存内,不会相隔太远,运行游戏改变donze的值,发现CB96处的值改变这里就是donze的值,因为要获取最大值直接输入ff,发现它往CB97的位置进了1位,于是把两边都改成FF FF发现值变成了负数,说明是有符号的,所以最大值应该是0111 1111 1111 1111,转成小端序就是FF 7F修改后就可以获得flag。
flag