
2025TPCTF部分Re-wp+复现
linuxpdf
pdf里运行Linux,010打开发现有一个base64解密函数,一些文件名以及文件对应的base64编码,通过正则匹配 ”文件名”: “文件内容“ 获取文件名和文件内容,直接用脚本导出。随便拿个文件看看信息,发现是zlib格式的压缩文件,用python的zlib库解压就行,查看解压出来有许多二进制文件,有一百多个有点不好看,于是寻找看是不是有elf可执行文件,写个函数遍历一下(脚本是AI写的)。
1 | import os |
最后发现在root_files_00000000000000a9.bin中有flag的逻辑。
MD5的特征值。
逻辑大概就是从前往后比较flag后n位(n从28到1,flag总共28字节)生成的MD5值。
爆破一下就行,注意密文中每组哈希值间有0作为分隔符,所以17字节为一组MD5。
1 | import hashlib |
chase
用fceux进行调试,amr search在吃豆的时候寻找改变的值,就可以发现0x84的数据是用于存储当前吃豆的数量,0x85好像是当前的关卡,是从0开始的。
用hexeditor修改值可以发现0x83就是目标的豆子数,直接修改关卡值好像会被检测输出hacker,于是继续修改豆子数来逐个通关,通过第五关后可以拿到第一段flag。
得到第一部分flag
在ppu viewer中看到了第三段flag

第三部分
在PPU viewer页面还可以看到字符表。 查询资料可知,NES 游戏中Tile是游戏中所使用一个图案块。游戏的一个画面就是由多个Tile组成的,每个Tile都有一个索引值便于调用显示。
在PPU viewer页面可以看到每个Tile的索引值(左下角)。
例如26就是上面F的值。。。,直接在010中搜索FLAG的Tile值(26 2C 21 27 )就可以找到对应FLAG这四个字符的tile值出现的位置,那么这个位置大概率就是flag在页面上出现的位置,提取下来,创建字符映射表映射回去就行。注意数字有两个表。
1 | table = list(range(32,91)) # 获取!~Z的ASCII码 |
解密得到flag的第二部分。
PLAY1N9_6@M3S_
最后的flag: TPCTF{D0_Y0U_L1KE_PLAY1N9_6@M3S_ON_Y0UR_N3S?}
magicfile
文件一般存储一个特征值来确定文件类型。linux通过一个libmagic.so来检测文件类型。文件类型被存储在一个magic文件内(magicfile),里面记录了文件类型(要比较的字节)和要比较的字节地址偏移,以及比较的数据类型。检测原理就是读取文件内容然后根据偏移的地址来获取数据与magic存储的内容进行比较。
本题模拟了libmagic.so的原理,我们输入的flag被作为文件内容进行文件检查。即flag与magic内的内容进行比较,正确则输出congratulations。我们的flag为48字节,如果直接存储在一个类型里那么就可以直接字符串找到flag,所以我们的flag一定是被分块了,而且是单字节。所以我们只需要挨个读取magic文件里比较的内容就行了。本题的magicfile已经被保存在数据段了,所以实现了自定义magic的比较。

首先我们需要了解magic文件是怎么存储信息的。我们在github上可以找到libmagic的源码,查看magic结构体
1 | struct magic { |
value节点中是需要进行比较的内容,看一下value的定义,联合体的大小是最大类型的大小
1 | union VALUETYPE { |
计算一下就可以知道magic结构体大小是376byte。我们可以遍历所有magic结构体,提取所有value位char的内容,flag估计就在里面。。看magic_load的magicfile变量可以看到程序的magic文件存在地址0x21004,后面的magiclen是magic文件大小。
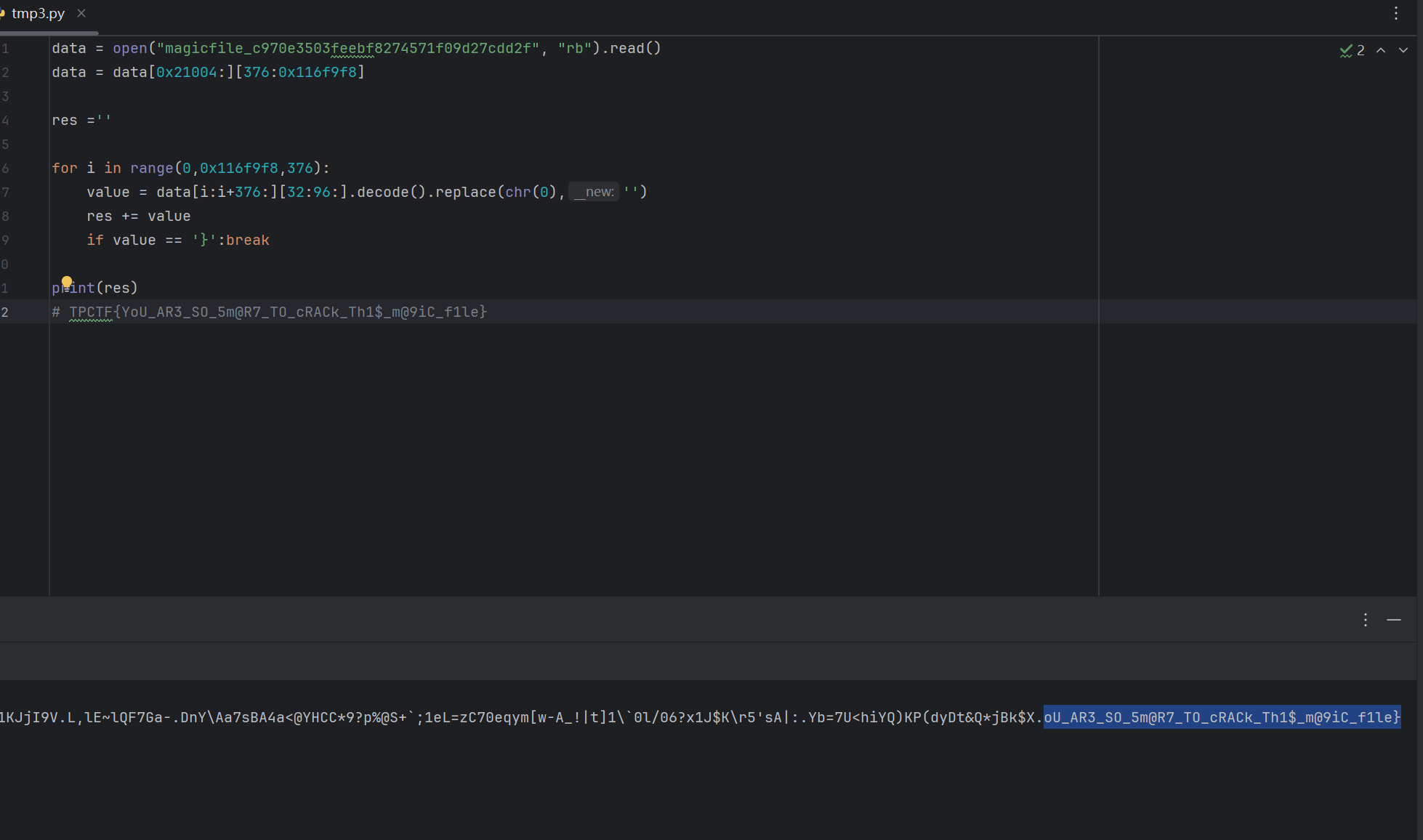
最后的flag要猜一下前面是个Y,最后结果是TPCTF{YoU_AR3_SO_5m@R7_TO_cRACk_Th1$_m@9iC_f1le}
1 |
|